

Nvidia just released a beta application for Windows called ChatWithRTX. It uses a local LLM to chat offline with your own files (currently .txt, .pdf, and .doc). The system requirements are Windows 11 and an Nvidia 30xx or 40xx video card with at least 8GB of RAM. I am running a 4070Ti with 12GB.
Before getting into the details, my first impression was very positive. It is an easy way to run a private AI and chat up your own documents. This is important for people and organizations that don't want to upload their documents to ChatGPT or another commercial service where the contents will be exposed. Using local embedded data has a name in LLM speak: Retrieval-augmented generation or RAG. ChatWithRTX is an easy to use RAG application.
Performance was snappy and the responses were pretty useful. It is in beta right now and I ran into some limitations, but the future is clear. Local AIs will be available for everyone's daily use, and soon!
Installation
The download was huge, about 38GB. Installation is as simple as running the setup.exe and taking the defaults. The default install location was in my user AppData directory, full path: C:\Users\username\AppData\Local\NVIDIA\ChatWithRTX. The installed application was also about 38GB and it put a shortcut on my desktop.
The application installs a custom python 3 environment (MiniConda) and uses an open source AI from Mistral (a French tech company that has several powerful models). The particular model is Mistral 7B (seven billion parameters) that has been quantized down to 4 bits. Quantization drops some precision in the model weights in order to have a smaller footprint in memory and also speeds up performance. As an aside, my experience is that 5 bits is the sweet spot in the trade off between performance and accuracy.
First Run
On launch, it opened a command line window, ran through some python environment configuration, and updated some model files. Then it launched a web service on a random high port on localhost (e.g., http://127.0.0.1:46197/). The port number changed each time I ran it.
It starts with a default data set of .txt files, most about PC games that run on Nvidia cards. You can ask questions and it will refer to the content of the text files for an answer. It also shows from which file it got the answer.
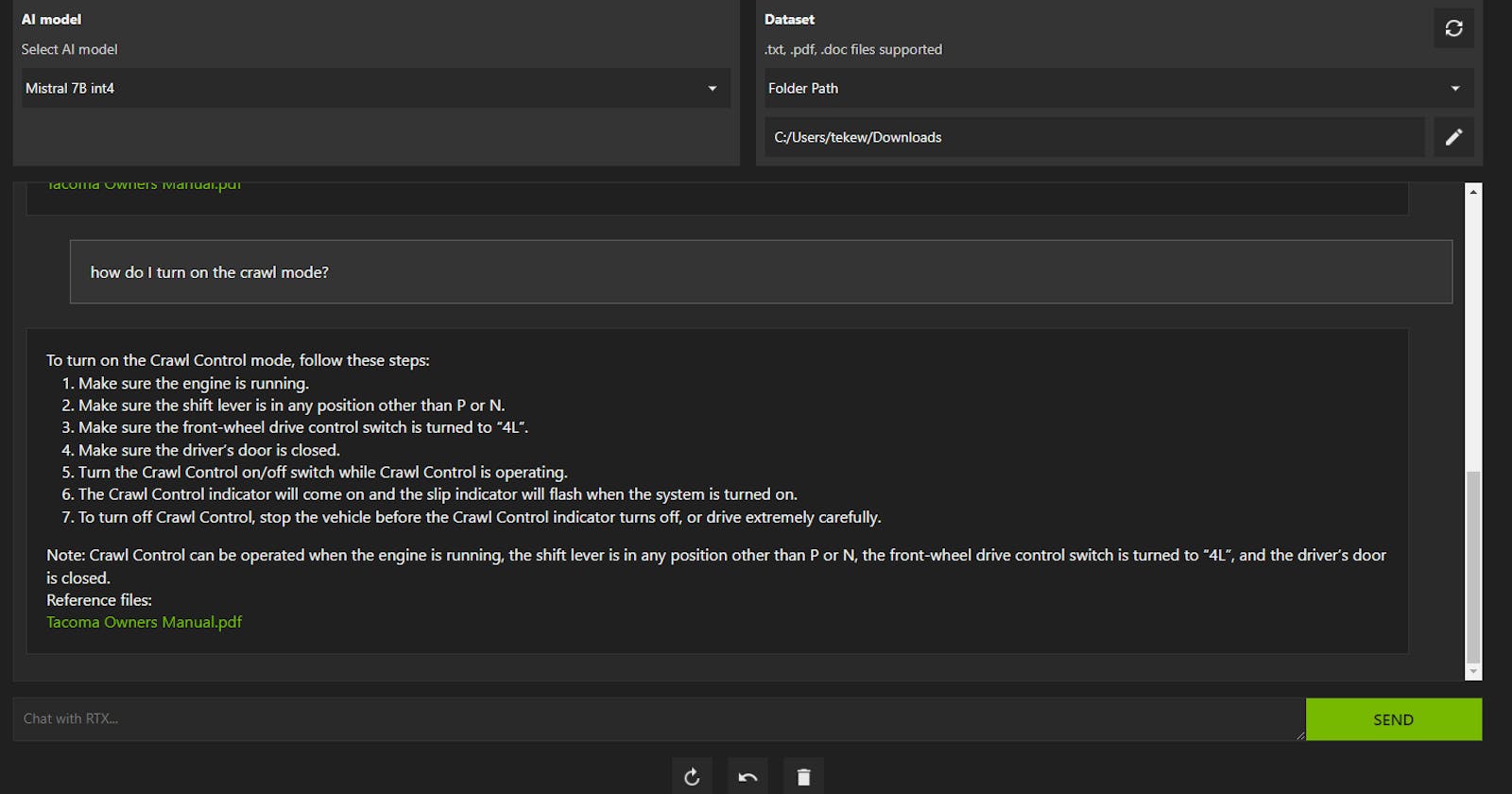
Chatting with my Tacoma Owners Manual
Once ChatWithRTX is running in your browser, you can point to different data folders.
When you change the dataset folder path, it will scan the directory recursively looking for files to ingest. It creates embeddings (converting the text into floating point vectors) and stores them in the application directory for use. I ran into a problem at first when I pointed it to ALL of my local data consisting of 240GB and thousands of files. It eventually choked trying to embed all of that data, and I had to stop and restart the app.
Next, I tried my Downloads directory where only a few PDFs lived, including the Tacoma Owners Manual. The embedding took less than a minute and you can see what is happening by watching the command line window.
I've been running local AIs in Ubuntu Linux using Ollama for a couple of months. I've run a couple of experiments with local embeddings and it took a long time to embed simple text documents. Whatever method ChatWithRTX used was fast by comparison.
When I asked it some random questions, it was pretty smart and gave me useful answers. The Mistral AI is not restricted to local data, it will gladly answer anything it can, like how to make chocolate chip cookies, but it will not run web searches.
Chatting with a YouTube video
You can also point to a YouTube URL (single video or playlist) and it can ingest the video content, converting it to a transcript and possibly creating new embeddings. To get the video transcripts, you give it the URL, then click what looks like a download button to the right of the URL. The transcript(s) are downloaded and embedded for use, just like a text file would be.
I tried it with a Jeff Nippard body building video and the transcript download completed in less than a minute. Then I was able to ask it a question and it provided the right answer. I thought that was impressive, most impressive.
Some Config Files
Poking around the app files, I found the startup configuration files in JSON (JavaScript Object Notation) format. The path to the config files: C:\Users\username\AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\config\.
There were three files in that directory:
app_config.json - some application settings, nothing worth changing
config.json - models installed and model settings (like temperature), and startup dataset to use
preferences.json - last dataset path used
When I crashed it by pointing it to all of local files, I was able to change the last dataset path in preferences.json so it would start up in my Downloads directory instead the next time. I didn't want it to get stuck in an endless loop of indigestion.
There was a Llama 2 13B model listed in the config.json file, but the installed status was False. This is probably a holdover from the TensorRT-LLM project that is used to speed up inference on Nvidia cores. Maybe other models will be DLC options in the future. Kudos to Nvidia for going out of their way to make local AIs easier to use.